DocMMIR: Cross-Domain Document Multimodal Retrieval Framework
Project Overview
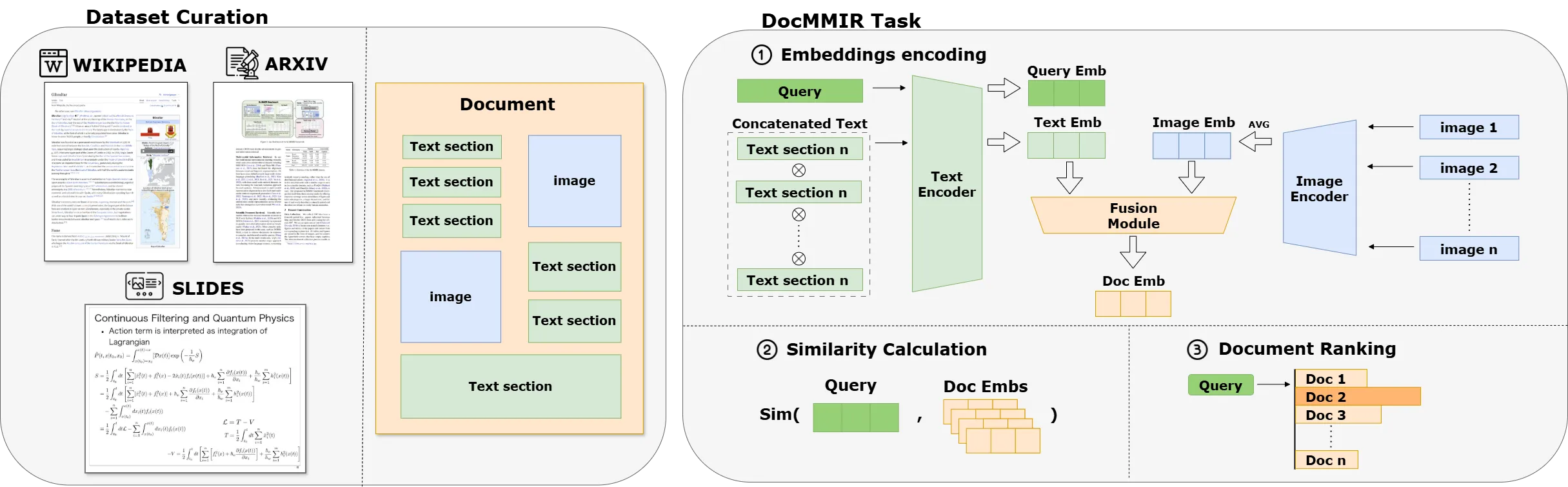
DocMMIR proposes a unified multimodal document retrieval framework that supports retrieval across various document formats including Wikipedia articles, arXiv papers, and Slideshare presentations. The framework encodes both text and images simultaneously, achieving significant improvements in cross-domain document retrieval performance through optimized fusion strategies and symmetric binary cross-entropy loss.
Dataset Construction
- Document Sources: WIT (Wikipedia), SciMMIR (arXiv), Slideshare-1M (Slideshare)
- Scale: 488,467 documents (Training 450,079 / Validation 19,184 / Test 19,204)
- Statistical Features:
- Wikipedia: Average 1.33 images, 380 tokens
- arXiv: Average 7.72 images, 766 tokens
- Slideshare: Average 30.43 images, 2,060 tokens
Model and Methods
- Dual Encoder Architecture:
- Text Encoding: Pre-trained Transformer, using [CLS] as text representation
- Image Encoding: ViT independent encoding, averaging all image embeddings
- Late Fusion:
[ E_{doc} = α·E_{text} + (1−α)·E_{img} ] - Training Objective: Symmetric Binary Cross-Entropy (BCE) loss, balancing query-document positive and negative samples
- Comparison Baselines: Zero-shot models including CLIP, ALIGN, BLIP-2, SigLIP-2, etc.
Experimental Setup
- Fine-tuned Model: OpenCLIP (ViT-L/14)
- Optimizer: AdamW (modal learning rate 2e-5, weight decay 0.01), linear warmup + cosine decay
- Training Details: 5 epochs, early stopping when validation performance plateaus
- Evaluation Metrics: MRR@10, NDCG@10, HIT@1/3/10
Experimental Results
- Overall Performance
- Zero-shot CLIP (ViT-L/14) full-set MRR@10 only 0.3091
- After fine-tuning, MRR@10 soars to 0.6993
- Fusion & Loss Comparison
- Weighted sum fusion + BCE optimal: Full-set MRR@10 = 0.6566
- MLP fusion or InfoNCE loss significantly underperform
- Modal Ablation
- Text dominates retrieval performance: Text-only model Full-set MRR@10 = 0.5333
- Multimodal fusion brings significant gains, especially in arXiv (from 0.2414 to 0.7144) and Wikipedia (from 0.6286 to 0.7728)
Learnings and Reflections
- Simple Fusion More Robust: Late weighted sum outperforms complex MLP structures in cross-domain retrieval.
- BCE Loss Advantage: Under moderate batch sizes, binary cross-entropy is more stable and efficient than InfoNCE.
- Data Domain Impact: Wikipedia’s rich text aids model generalization, but layout-dense Slides require more refined layout-aware fusion strategies.